在互联网时代,信息量巨大,如何高效地获取和处理这些信息变得尤为重要。Python 爬虫作为一种自动化获取网页信息的技术,已成为许多程序员和数据分析师必备技能之一。本文将深入探讨 Python 爬虫背后的技术原理,并结合实际代码示例来讲解其工作流程。
第一部分:Python 爬虫基础知识
1.1 爬虫概述
爬虫是一种自动化获取网页信息的程序。它通过模拟浏览器的行为,向目标网站发送 HTTP 请求,解析 HTML 内容,提取所需信息,并将数据存储在本地或上传到其他系统中。
1.2 爬虫的作用
爬虫的主要作用包括:
- 数据采集:从各种网站中获取有价值的数据,为数据分析提供原始数据。
- 信息检索:根据关键词在互联网上搜索相关信息,为用户提供便捷的检索服务。
- 自动化测试:模拟用户行为,对网站进行自动化测试,发现潜在问题。
- 网络爬虫技术:为搜索引擎提供数据来源,提高搜索结果的质量。
1.3 Python 爬虫的优势
Python 是一种简洁、易学、功能强大的编程语言,其丰富的库和框架为爬虫开发提供了极大的便利。Python 爬虫的优势主要包括:
- 丰富的库支持:如 requests、BeautifulSoup、Scrapy 等,满足各种爬虫需求。
- 简洁的语法:易于理解和编写,降低开发成本。
- 跨平台运行:可在多种操作系统上运行,如 Windows、Linux、macOS 等。
- 强大的社区支持:丰富的文档和案例,方便学习和交流。
1.4 Python 爬虫的分类
Python 爬虫可分为两大类:
- 通用爬虫:如 Google、Baidu 等搜索引擎的爬虫,旨在为用户提供广泛的搜索结果。
- 聚焦爬虫:根据特定需求,从互联网上抓取相关信息的爬虫,如新闻网站、电商网站的爬虫。
1.5 Python 爬虫的工作流程
Python 爬虫的工作流程主要包括以下几个步骤:
- 发送请求:通过 requests 库向目标网站发送 HTTP 请求。
- 解析响应:获取网页 HTML 内容,解析其中的有用信息。
- 提取数据:根据需求,提取网页中的有用数据。
- 存储数据:将提取的数据存储在本地或上传到其他系统中。
1.6 Python 爬虫的常见问题
在爬虫开发过程中,可能会遇到以下常见问题:
- 反爬虫策略:目标网站采取各种手段防止爬虫,如验证码、IP 限制等。
- 数据提取困难:目标网站结构复杂,难以定位和提取所需数据。
- 并发控制:爬虫对目标网站的访问速度过快,可能导致服务器压力过大。
- 法律法规遵守:在爬取数据时,需遵守相关法律法规,尊重网站版权。
1.7 Python 爬虫的道德和法律规范
在爬取数据时,应遵循以下道德和法律规范:
- 尊重网站版权:不爬取受版权保护的内容,如文章、图片、视频等。
- 遵守网站规定:不违反目标网站的使用条款,如爬取频率限制等。
- 保护个人隐私:不爬取涉及个人隐私的数据,如姓名、电话、地址等。
- 合理使用数据:不将爬取的数据用于非法用途,如发送垃圾邮件、诈骗等。
1.8 示例代码:使用 requests 库发送 HTTP 请求
以下是一个简单的 Python 爬虫示例,使用 requests 库向百度发送 HTTP 请求,并获取网页内容。
import requests
# 发送 HTTP 请求
url = "http://www.baidu.com"
response = requests.get(url)
# 打印网页内容
print(response.text)
通过以上代码,我们向百度发送了一个 GET 请求,并打印了网页内容。这只是 Python 爬虫的基础知识,后续章节将详细讲解爬虫的其他技术和高级用法。
第二部分:HTML 解析技术
2.1 HTML 简介
HTML(HyperText Markup Language)是一种标记语言,用于创建网页和网络应用。它使用标签来描述网页的结构和内容。HTML 解析是爬虫中的一个重要环节,它涉及从网页中提取有用信息的过程。
2.2 解析 HTML 的方法
解析 HTML 有多种方法,包括:
- 正则表达式:通过正则表达式匹配和提取 HTML 中的文本信息。
- DOM 解析:使用文档对象模型(Document Object Model)解析 HTML 结构。
- XPath:通过 XPath 表达式定位和提取 HTML 中的元素。
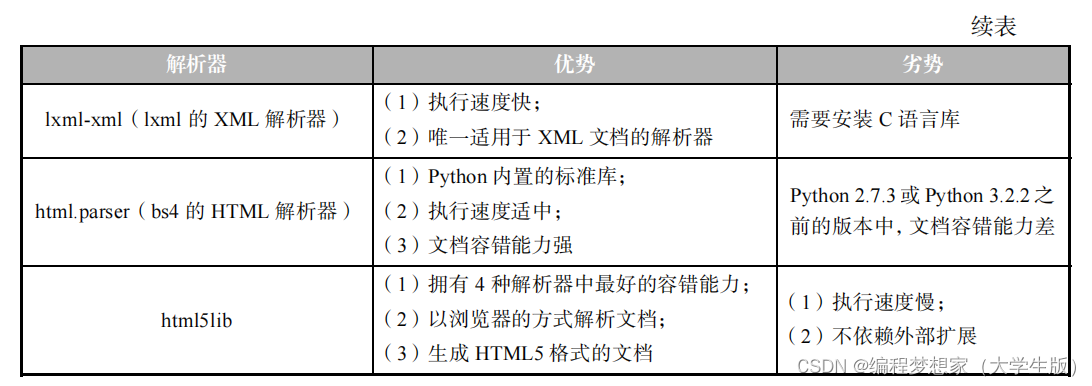
2.3 BeautifulSoup 库简介
BeautifulSoup 是一个用于解析 HTML 和 XML 文档的 Python 库。它提供了一个简单而强大的接口,用于从网页中提取数据。
2.4 使用 BeautifulSoup 解析 HTML
以下是一个使用 BeautifulSoup 解析 HTML 的示例:
from bs4 import BeautifulSoup
# 获取网页内容
html_content = """
<html>
<head>
<title>示例网页</title>
</head>
<body>
<h1>这是一个标题</h1>
<p>这是一个段落。</p>
</body>
</html>
"""
# 创建 BeautifulSoup 对象
soup = BeautifulSoup(html_content, 'html.parser')
# 提取标题
title = soup.find('title').text
# 提取段落
paragraph = soup.find('p').text
# 打印提取的内容
print(title)
print(paragraph)
在这个示例中,我们首先创建了一个 BeautifulSoup 对象,然后使用 find 方法定位 HTML 中的元素,并提取其文本内容。
2.5 XPath 简介
XPath 是一种用于在 XML 文档中定位节点和选择节点的语言。它提供了比 CSS 选择器更强大的功能,可以定位复杂的 HTML 结构。
2.6 使用 XPath 解析 HTML
以下是一个使用 XPath 解析 HTML 的示例:
from lxml import etree
# 获取网页内容
html_content = """
<html>
<head>
<title>示例网页</title>
</head>
<body>
<h1>这是一个标题</h1>
<p>这是一个段落。</p>
</body>
</html>
"""
# 创建 XPath 对象
root = etree.HTML(html_content)
# 提取标题
title = root.xpath('//title/text()')[0]
# 提取段落
paragraph = root.xpath('//p/text()')[0]
# 打印提取的内容
print(title)
print(paragraph)
在这个示例中,我们使用 XPath 表达式定位 HTML 中的元素,并提取其文本内容。
第三部分:数据提取与存储
3.1 数据提取方法
在爬虫中,数据提取是核心环节。常见的数据提取方法包括:
- 属性提取:通过标签的属性(如 href、src 等)获取链接和图片地址等。
- 文本提取:直接提取标签内的文本内容。
- 列表提取:提取包含多个元素的列表,如表格中的多行数据。
3.2 数据存储方法
提取的数据需要存储在本地或上传到其他系统中。常见的数据存储方法包括:
- 文件存储:将数据写入本地文件,如 CSV、JSON 等。
- 数据库存储:将数据插入数据库表中。
- API 调用:将数据上传到其他系统,如调用第三方 API。
3.3 示例代码:使用 requests 和 BeautifulSoup 提取数据,并存储到 JSON 文件
以下是一个使用 requests 和 BeautifulSoup 提取数据,并存储到 JSON 文件中的示例:
import requests
from bs4 import BeautifulSoup
import json
# 发送 HTTP 请求
url = "http://www.example.com"
response = requests.get(url)
# 解析 HTML
soup = BeautifulSoup(response.text, 'html.parser')
# 提取数据
data = []
for i in range(1, 11): # 假设我们要提取前 10 行数据
row = {
'序号': i,
'列1': soup.find('tr', {'id': f'row{i}'}).find('td', {'class': 'col1'}).text,
'列2': soup.find('tr', {'id': f'row{i}'}).find('td', {'class': 'col2'}).text
}
data.append(row)
# 存储数据到 JSON 文件
with open('data.json', 'w', encoding='utf-8') as file:
json.dump(data, file, ensure_ascii=False, indent=4)
在这个示例中,我们首先使用 requests 向目标网站发送 HTTP 请求,然后使用 BeautifulSoup 解析 HTML。接着,我们提取表格中的数据,并将其存储到 JSON 文件中。
通过以上步骤,我们可以有效地提取和存储网页中的数据,为后续的数据分析和处理提供支持。
第四部分:反爬虫策略与应对措施
4.1 反爬虫策略概述
随着爬虫技术的普及,许多网站采取了各种反爬虫策略,以防止自动化工具对其网站造成的影响。常见的反爬虫策略包括:
- 验证码:要求用户输入验证码,以证明是真实用户访问。
- IP 限制:限制单个 IP 地址的访问频率,超过限制则禁止访问。
- Referer 检查:检查请求的 Referer 头部,确保请求来自合法来源。
- Cookies 检查:检查请求的 Cookies,确保请求包含正确的 Cookies。
- 登录限制:某些内容需要登录后才能访问,未登录用户无法获取。
4.2 应对措施
面对反爬虫策略,爬虫开发者需要采取相应的应对措施。常见的应对措施包括:
- 模拟登录:使用 Python 中的 requests 库模拟登录过程,获取登录后的 Cookies。
- 设置 User-Agent:在请求头中设置 User-Agent,使其看起来像真实浏览器。
- 调整访问频率:控制爬虫的访问频率,避免对目标网站造成过大压力。
- 代理池:使用代理服务器进行访问,以避免 IP 限制。
- 多线程爬虫:使用多线程或多进程爬虫,提高爬取效率。
4.3 示例代码:使用 requests 模拟登录
以下是一个使用 requests 模拟登录的示例:
import requests
# 登录 URL
login_url = "http://www.example.com/login"
# 登录数据
login_data = {
'username': 'your_username',
'password': 'your_password'
}
# 发送登录请求
response = requests.post(login_url, data=login_data)
# 检查登录是否成功
if response.status_code == 200:
print("登录成功")
# 获取登录后的 Cookies
cookies = response.cookies
else:
print("登录失败")
在这个示例中,我们使用 requests 发送 POST 请求,并传入登录数据。如果响应状态码为 200,则表示登录成功,并获取登录后的 Cookies。
4.4 示例代码:使用代理服务器
以下是一个使用代理服务器进行访问的示例:
import requests
# 代理服务器地址
proxy_url = "http://127.0.0.1:8080"
# 发送请求,使用代理服务器
response = requests.get("http://www.example.com", proxies={"http": proxy_url, "https": proxy_url})
# 打印响应内容
print(response.text)
在这个示例中,我们使用 requests 发送 GET 请求,并传入代理服务器地址。这样,请求将通过代理服务器发送,以避免 IP 限制。
通过以上措施,我们可以有效地应对目标网站的反爬虫策略,提高爬虫的效率和可靠性。
第五部分:法律法规与道德规范
5.1 法律法规遵守
在爬取数据时,应遵守相关法律法规,尊重网站版权。常见的法律法规包括:
- 著作权法:不爬取受版权保护的内容,如文章、图片、视频等。
- 网络安全法:不进行非法的网络攻击行为,如 DDoS 攻击。
- 反不正当竞争法:不进行不正当竞争行为,如恶意爬取竞争对手数据。
5.2 道德规范遵守
在爬取数据时,应遵循以下道德规范:
- 尊重网站规定:不违反目标网站的使用条款,如爬取频率限制等。
- 保护个人隐私:不爬取涉及个人隐私的数据,如姓名、电话、地址等。
- 合理使用数据:不将爬取的数据用于非法用途,如发送垃圾邮件、诈骗等。
5.3 示例代码:遵守法律法规与道德规范
以下是一个遵守法律法规与道德规范的示例:
import requests
from bs4 import BeautifulSoup
# 发送 HTTP 请求
url = "http://www.example.com"
response = requests.get(url)
# 解析 HTML
soup = BeautifulSoup(response.text, 'html.parser')
# 提取数据
data = []
for i in range(1, 11): # 假设我们要提取前 10 行数据
row = {
'序号': i,
'列1': soup.find('tr', {'id': f'row{i}'}).find('td', {'class': 'col1'}).text,
'列2': soup.find('tr', {'id': f'row{i}'}).find('td', {'class': 'col2'}).text
}
data.append(row)
# 存储数据到本地文件
with open('data.txt', 'w', encoding='utf-8') as file:
for row in data:
file.write(f"序号: {row['序号']}, 列1: {row['列1']}, 列2: {row['列2']}\n")
在这个示例中,我们首先使用 requests 向目标网站发送 HTTP 请求,然后使用 BeautifulSoup 解析 HTML。接着,我们提取表格中的数据,并将其存储到本地文件中。在存储数据时,我们遵循了以下原则:
- 只爬取公开可用的数据,不爬取受版权保护的内容。
- 尊重目标网站的使用条款,不违反爬取频率限制。
- 保护个人隐私,不爬取涉及个人隐私的数据。
- 合理使用数据,不将爬取的数据用于非法用途。
通过以上步骤,我们可以确保在爬取数据时遵守法律法规和道德规范,尊重网站版权和用户隐私。
总结
Python 爬虫技术是一种高效的数据采集手段,但同时也需要遵守相关法律法规和道德规范。本文详细介绍了 Python 爬虫背后的技术原理,包括 HTML 解析技术、数据提取与存储方法、反爬虫策略与应对措施以及法律法规与道德规范。
通过学习本文,我们了解到 Python 爬虫的工作流程,包括发送请求、解析响应、提取数据和存储数据。同时,我们也掌握了如何使用 BeautifulSoup 和 XPath 解析 HTML,以及如何使用 requests 和 BeautifulSoup 提取数据并存储到文件或数据库中。
在面对反爬虫策略时,我们了解了常见的反爬虫策略,如验证码、IP 限制、Referer 检查等,并学习了如何采取相应的应对措施,如模拟登录、设置 User-Agent、调整访问频率、使用代理池和多线程爬虫等。
最后,我们强调了在爬取数据时应遵守的法律法规和道德规范,包括尊重网站版权、保护个人隐私和合理使用数据等。
掌握 Python 爬虫技术,不仅能够帮助我们高效地获取和处理数据,还能够帮助我们遵守法律法规和道德规范,尊重网站版权和用户隐私。随着爬虫技术的不断发展,我们应不断学习和实践,提高自己的技术水平,为数据采集和分析领域做出更大的贡献。